Folding@Home Benchmark 1.2.0 (GUI)
Moderators: Site Moderators, FAHC Science Team
-
proteneer
- Pande Group Member
- Posts: 148
- Joined: Fri Sep 28, 2012 11:03 pm
- Location: Stanford, CA
- Contact:
Re: Folding@Home Benchmark Beta Testing
PS - Anandtech promised to play around with the benchmarks this week too ^_^
-
PinHead
- Posts: 285
- Joined: Tue Jan 24, 2012 3:43 am
- Hardware configuration: Quad Q9550 2.83 contains the GPU 57xx - running SMP and GPU
Quad Q6700 2.66 running just SMP
2P 32core Interlagos SMP on linux
Re: Folding@Home Benchmark Beta Testing
upgraded the ATI/AMD HD57xx drivers from Catalyist 11.12 to Catalyist 12.8 and now OpenCL runs.proteneer wrote:Do you guys have the latest drivers?
Win 7 64bit
Catalyist 12.8
AMD/ATI HD5700 series
FAHBench v 0.3
Open CL Single Precision
Explicit
5.05426 ns/day
Implicit
42.1176 ns/day
Open CL Double Precision
Explicit
"This device does not support double precision"
-
proteneer
- Pande Group Member
- Posts: 148
- Joined: Fri Sep 28, 2012 11:03 pm
- Location: Stanford, CA
- Contact:
Re: Folding@Home Benchmark Beta Testing
Ok thanks - that makes sense =)
-
PinHead
- Posts: 285
- Joined: Tue Jan 24, 2012 3:43 am
- Hardware configuration: Quad Q9550 2.83 contains the GPU 57xx - running SMP and GPU
Quad Q6700 2.66 running just SMP
2P 32core Interlagos SMP on linux
Re: Folding@Home Benchmark Beta Testing
That was with Version 0_1, Version 0_3 seems to work fine!proteneer wrote:Is this with Version 0_2?PinHead wrote:It doesn't seem to like Nvidia/Nvidia either:
Vista Ultimate 32 bit, Tesla C2050 and GTX550Ti
FAHBench.exe --display-devices
Output:Tesla C2050 WDDM mode ( OpenCL )Code: Select all
O O P R O T E N E E R C--N \ \ N | C C=O / \-C C / | N-C \ .C-C C/ C C | C / \ O | | / N | C C | | O C C /-C \_N_/ \ N _C_ C | / O / C C-/ \_C/ \N-/ \ N /-C-\ C | | O / | | C-/ \C/ N-/ \_ N\ /C\ -C N | | O | | | \C/ C/ N/ \_C__/ \ C-\ C C O | | | | C-/ N/ \-C \_C C O | O | | \ \-O C C O | \ \ C N Folding@Home C--N C \ | Benchmark (Beta) | | N--C O | \ Yutong Zhao C=O N [email protected] / O for official stats, please visit http://www.fahbench.com === 1 OpenCL platform(s) found: === -- 0 -- PROFILE = FULL_PROFILE VERSION = OpenCL 1.1 CUDA 4.2.1 NAME = NVIDIA CUDA VENDOR = NVIDIA Corporation EXTENSIONS = cl_khr_byte_addressable_store cl_khr_icd cl_khr_gl_sharing cl_nv_d3d9_sharing cl_nv_d3d10_sharing cl_khr_d3d10_sharing cl_nv_d3d11_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_nv_pragma_unroll === 1 OpenCL device(s) found on platform: -- 0 -- DEVICE_NAME = Tesla C2050 / C2070 DEVICE_VENDOR = NVIDIA Corporation DEVICE_VERSION = OpenCL 1.1 CUDA DRIVER_VERSION = 306.94 DEVICE_MAX_COMPUTE_UNITS = 14 DEVICE_MAX_CLOCK_FREQUENCY = 1147 DEVICE_GLOBAL_MEM_SIZE = 2818572288 -- 1 -- DEVICE_NAME = GeForce GTX 550 Ti DEVICE_VENDOR = NVIDIA Corporation DEVICE_VERSION = OpenCL 1.1 CUDA DRIVER_VERSION = 306.94 DEVICE_MAX_COMPUTE_UNITS = 4 DEVICE_MAX_CLOCK_FREQUENCY = 1962 DEVICE_GLOBAL_MEM_SIZE = 1073741824 Invalid Platform (please use either OpenCL or CUDA)
FAHBench.exe -deviceId 0 -platform OpenCL -precision single
Explicit:
13.5521 ns/day ( accuracy really beats on the slow drive, factor ? )
Implicit:
61.4903 ns/day
GTX550Ti ( OpenCL )FAHBench.exe -deviceId 1 -platform OpenCL -precision single
Explicit:
8.40868 ns/day
Implicit:
36.6661 ns/day
Tesla C2050 WDDM mode ( CUDA )FAHBench.exe -deviceId 0 -platform CUDA -precision single
Explicit:
15.8791 ns/day
Implicit:
55.0354 ns/day
GTX550Ti ( CUDA )FAHBench.exe -deviceId 1 -platform CUDA -precision single
Explicit:
Error launching CUDA compiler:-1
nvcc : fatal error : Value 'compute_21' is not defined for option
'gpu-architecture'
c:\FAHBench_0_3>FAHBench.exe --display-devices
[1] compatible platform(s):
-- 0 --
PROFILE = FULL_PROFILE
VERSION = OpenCL 1.1 CUDA 4.2.1
NAME = NVIDIA CUDA
VENDOR = NVIDIA Corporation
(2) device(s) found on platform 0:
-- 0 --
DEVICE_NAME = Tesla C2050 / C2070
DEVICE_VENDOR = NVIDIA Corporation
DEVICE_VERSION = OpenCL 1.1 CUDA
-- 1 --
DEVICE_NAME = GeForce GTX 550 Ti
DEVICE_VENDOR = NVIDIA Corporation
DEVICE_VERSION = OpenCL 1.1 CUDA
Invalid Platform (please use either OpenCL or CUDA)
Tesla C2050
c:\FAHBench_0_3>FAHBench.exe -platformId 0 -deviceId 0 -platform OpenCL -precision single --disable-splash
Explicit:
Checking for accuracy...done
13.5529 ns/day
Implicit:
Checking for accuracy...done
61.5779 ns/day
c:\FAHBench_0_3>FAHBench.exe -platformId 0 -deviceId 0 -platform OpenCL -precision double --disable-splash
Explicit:
Checking for accuracy...done
7.24334 ns/day
Implicit:
Checking for accuracy...done
10.7788 ns/day
c:\FAHBench_0_3>FAHBench.exe -deviceId 0 -platform CUDA -precision single --disable-splash
Explicit:
Checking for accuracy...done
15.885 ns/day
Implicit:
Checking for accuracy...done
55.1865 ns/day
c:\FAHBench_0_3>FAHBench.exe -deviceId 0 -platform CUDA -precision double --disable-splash
Explicit:
Checking for accuracy...done
7.16828 ns/day
Implicit:
Checking for accuracy...done
11.0659 ns/day
GTX 550Ti
c:\FAHBench_0_3>FAHBench.exe -platformId 0 -deviceId 1 -platform OpenCL -precision single --disable-splash
Explicit:
Checking for accuracy...done
8.56641 ns/day
Implicit:
Checking for accuracy...done
42.1772 ns/day
c:\FAHBench_0_3>FAHBench.exe -platformId 0 -deviceId 1 -platform OpenCL -precision double --disable-splash
Explicit:
Checking for accuracy...done
2.51918 ns/day
Implicit:
Checking for accuracy...done
3.38533 ns/day
c:\FAHBench_0_3>FAHBench.exe -deviceId 1 -platform CUDA -precision single --disable-splash
Explicit:
Checking for accuracy...done
11.3592 ns/day
Implicit:
Checking for accuracy...done
20.203 ns/day
c:\FAHBench_0_3>FAHBench.exe -deviceId 1 -platform CUDA -precision double --disable-splash
Explicit:
Checking for accuracy...done
2.914 ns/day
Implicit:
Checking for accuracy...done
3.95735 ns/day
Re: Folding@Home Benchmark Beta Testing
I'll see about giving my 3 x 580SCs and 2 x 590 Classifieds a run on this either today or tomorrow.proteneer wrote:nice - its a nice list of numbers the you guys are getting. the numbers are going to vary in the upcoming months, as we begin to heavily optimize OpenMM. I trust all of you guys here, but you might want to mention that those numbers are on unofficial - it's pretty easy to hack so we keep an official list on fahbench.com as well.
You can keep both the CUDA/OpenCL numbers, we care more about single precision perf. at this point. Don't really need double (though it is one area in which the K20 shines).
PS - does anyone have overclocked 580? That card is a BEAST.
EDIT 1: 1:30 PM EST January 19, 2013
Added 590 info here: viewtopic.php?f=38&t=23440&start=15#p234172
FAHBench ran fine as far as I can tell.

folding@evga - Donor Advisory Board Representative
-
proteneer
- Pande Group Member
- Posts: 148
- Joined: Fri Sep 28, 2012 11:03 pm
- Location: Stanford, CA
- Contact:
Re: Folding@Home Benchmark Beta Testing
quick heads up - next update (not released yet) will allow MULTIPLE GPUs to WORK TOGETHER
Re: Folding@Home Benchmark Beta Testing
Fascinating. How similar will they have to be? Exact same card? same family, or any two GPUs that meet base requirements?proteneer wrote:quick heads up - next update (not released yet) will allow MULTIPLE GPUs to WORK TOGETHER
-
Evil Penguin
- Posts: 146
- Joined: Sun Apr 13, 2008 4:34 am
- Location: Texas, United States
Re: Folding@Home Benchmark Beta Testing
I don't think he meant multiple cards working on the very same WU (like SLI or something).k1wi wrote:Fascinating. How similar will they have to be? Exact same card? same family, or any two GPUs that meet base requirements?proteneer wrote:quick heads up - next update (not released yet) will allow MULTIPLE GPUs to WORK TOGETHER
Just multiple instances at the same time.
-
proteneer
- Pande Group Member
- Posts: 148
- Joined: Fri Sep 28, 2012 11:03 pm
- Location: Stanford, CA
- Contact:
Re: Folding@Home Benchmark Beta Testing
no actually i do mean 2 cards working on the same WU - the problem is that kinda don't scale very well when testing internally (and they only work on explicit). I'll probably need to add another flag specifying explicit/implicit
-
Evil Penguin
- Posts: 146
- Joined: Sun Apr 13, 2008 4:34 am
- Location: Texas, United States
Re: Folding@Home Benchmark Beta Testing
I think you would have better luck running multiple WUs on the same GPU (utilization).proteneer wrote:no actually i do mean 2 cards working on the same WU - the problem is that kinda don't scale very well when testing internally (and they only work on explicit). I'll probably need to add another flag specifying explicit/implicit - so sorry if I end up breaking all your batch files =P
I believe some GPUs can allocate a certain amount of SPUs to different tasks.
Not sure about that...
Also, isn't there a bit of a problem with smaller proteins not scaling too well with more SPUs?
-
proteneer
- Pande Group Member
- Posts: 148
- Joined: Fri Sep 28, 2012 11:03 pm
- Location: Stanford, CA
- Contact:
Re: Folding@Home Benchmark Beta (0.4 Latest)
Updated - 0.4 released, can now do multiple GPUs on same device.
"I think you would have better luck running multiple WUs on the same GPU (utilization)."
In FAH we highly prefer longer trajectories of a single simulation when possible.
"I think you would have better luck running multiple WUs on the same GPU (utilization)."
In FAH we highly prefer longer trajectories of a single simulation when possible.
-
P5-133XL
- Posts: 2948
- Joined: Sun Dec 02, 2007 4:36 am
- Hardware configuration: Machine #1:
Intel Q9450; 2x2GB=8GB Ram; Gigabyte GA-X48-DS4 Motherboard; PC Power and Cooling Q750 PS; 2x GTX 460; Windows Server 2008 X64 (SP1).
Machine #2:
Intel Q6600; 2x2GB=4GB Ram; Gigabyte GA-X48-DS4 Motherboard; PC Power and Cooling Q750 PS; 2x GTX 460 video card; Windows 7 X64.
Machine 3:
Dell Dimension 8400, 3.2GHz P4 4x512GB Ram, Video card GTX 460, Windows 7 X32
I am currently folding just on the 5x GTX 460's for aprox. 70K PPD - Location: Salem. OR USA
Re: Folding@Home Benchmark Beta (0.4 Latest)
[email protected], 4GB RAM, 2x GTX450@825/1848; x64 Win7 SP1 Nvidia v306.94
This gives single GTX460 data to compare against the dual SMP GTX460 data.
This gives single GTX460 data to compare against the dual SMP GTX460 data.
Code: Select all
C:\Temp\FAHBench_0_4>fahbench -deviceId 0 -platform CUDA -precision single --disable-accuracy-check
O O
P R O T E N E E R C--N \ \ N
| C C=O / \-C
C / | N-C \
.C-C C/ C C | C
/ \ O | | / N |
C C | | O C C /-C
\_N_/ \ N _C_ C | / O / C
C-/ \_C/ \N-/ \ N /-C-\ C | | O /
| | C-/ \C/ N-/ \_ N\ /C\ -C N | |
O | | | \C/ C/ N/ \_C__/ \ C-\ C
C O | | | | C-/ N/ \-C
\_C C O | O | |
\ \-O C C O
| \ \
C N Folding@Home C--N C
\ | Benchmark (Beta) | |
N--C O |
\ Yutong Zhao C=O
N [email protected] /
O
for official stats, please visit www.fahbench.com
Explicit:
Accuracy checking disabled.
14.2741 ns/day
Implicit:
Accuracy checking disabled.
56.962 ns/day
C:\Temp\FAHBench_0_4>fahbench -deviceId 0 -platform CUDA -precision double --disable-splash --disable-accuracy-check
Explicit:
Accuracy checking disabled.
3.94604 ns/day
Implicit:
Accuracy checking disabled.
5.61699 ns/day
C:\Temp\FAHBench_0_4>fahbench -deviceId 0 -platform OpenCL -precision single --disable-splash --disable-accuracy-check
Warning: Using OpenCL platform but no platformId specified, setting platformId=0
Explicit:
Accuracy checking disabled.
10.2394 ns/day
Implicit:
Accuracy checking disabled.
52.4224 ns/day
C:\Temp\FAHBench_0_4>fahbench -deviceId 0 -platform OpenCL -precision double --disable-splash --disable-accuracy-check
Warning: Using OpenCL platform but no platformId specified, setting platformId=0
Explicit:
Accuracy checking disabled.
3.40654 ns/day
Implicit:
Accuracy checking disabled.
4.85512 ns/day
C:\Temp\FAHBench_0_4>fahbench -deviceId 0,1 -platform CUDA -precision single --disable-splash --disable-accuracy-check
Explicit:
Accuracy checking disabled.
22.9827 ns/day
Implicit not supported on multiple devices.
C:\Temp\FAHBench_0_4>fahbench -deviceId 0,1 -platform CUDA -precision double --disable-splash --disable-accuracy-check
Explicit:
Accuracy checking disabled.
7.089 ns/day
Implicit not supported on multiple devices.
C:\Temp\FAHBench_0_4>fahbench -deviceId 0,1 -platform OpenCL -precision single --disable-splash --disable-accuracy-check
Warning: Using OpenCL platform but no platformId specified, setting platformId=0
Explicit:
Accuracy checking disabled.
17.0206 ns/day
Implicit not supported on multiple devices.
C:\Temp\FAHBench_0_4>fahbench -deviceId 0,1 -platform OpenCL -precision double --disable-splash --disable-accuracy-check
Warning: Using OpenCL platform but no platformId specified, setting platformId=0
Explicit:
Accuracy checking disabled.
6.16491 ns/day
Implicit not supported on multiple devices.
Re: Folding@Home Benchmark Beta Testing
That may be a bit of an understatement. I did a small check using CUDA and my 590s. Adding one gpu increased the performance by about 33%, adding a third gpu increased the performance about another 25% of the original score, and then a fourth showed no improvement over three. This was done on the same 590s I posted about in the other thread (linked above), but I had a couple of additional things running that may have reduced scores from yesterday. I will have to run this again when I have nothing else to do on this computer to see if the reduction seen on a single gpu from yesterday to today was because of other processes or the change from v0.3 to v0.4.proteneer wrote:no actually i do mean 2 cards working on the same WU - the problem is that kinda don't scale very well when testing internally (and they only work on explicit). I'll probably need to add another flag specifying explicit/implicit - so sorry if I end up breaking all your batch files =P
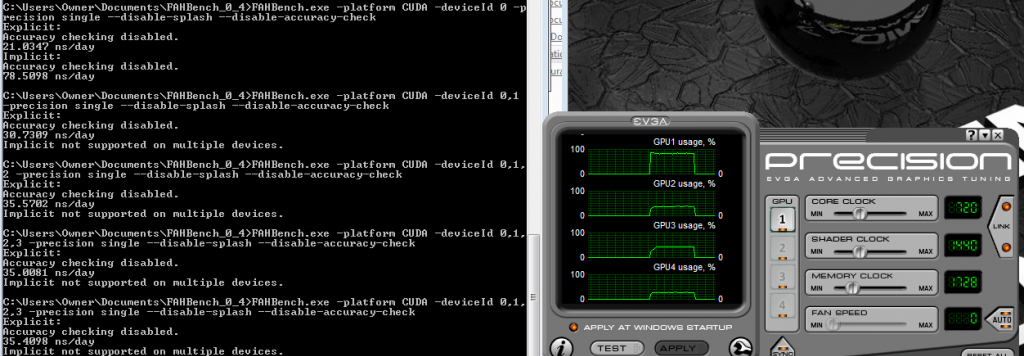
folding@evga - Donor Advisory Board Representative
Re: Folding@Home Benchmark Beta Testing
proteneer wrote:Unfortunately yes. The CUDA platform does a lot of JIT compilation and hence requires the nvcc compiler. We assume the user has the NVIDIA GPU COMPUTING TOOLKIT 5.0 installed (and hence why its able to find CUFF).Napoleon wrote:Do I actually have to install the whole CUDA5 Toolkit to try this? I've got Visual Studio Express already, as well as NVidia 310.90 WHQL driver, which does have CUDA5 support.
Did this ever get resolved? I have 0.4 and without installing the toolkit I ran the http://www.dependencywalker on the OpenMMOpenCL.dll file that came with the benchmark. I don't know if you're still interested in the results.proteneer wrote:Updated the download with some additional libraries - please redownload. Should fix OpenMMOpenCL.dll errors.
Code: Select all
Error: At least one required implicit or forwarded dependency was not found.
Error: At least one module has an unresolved import due to a missing export function in an implicitly dependent module.
Error: Modules with different CPU types were found.
Warning: At least one delay-load dependency module was not found.
Warning: At least one module has an unresolved import due to a missing export function in a delay-load dependent module.
CUFFT32_50-35.DLL
MVSCR90.DLL
IESHIMS.DLL
I'm not sure if you ever want to make FAHBench download all it's dependencies, but if you do, I though this might help.
I'll install the toolkit now.
In the meantime, plain vanilla (no overclock):
Code: Select all
C:\Users\bruce\FAHBench_0_4>FAHBench.exe --display-devices --disable-splash
[1] compatible platform(s):
-- 0 --
PROFILE = FULL_PROFILE
VERSION = OpenCL 1.1 CUDA 4.2.1
NAME = NVIDIA CUDA
VENDOR = NVIDIA Corporation
(1) device(s) found on platform 0:
-- 0 --
DEVICE_NAME = GeForce GTX 650 Ti
DEVICE_VENDOR = NVIDIA Corporation
DEVICE_VERSION = OpenCL 1.1 CUDA
Invalid Platform (please use either OpenCL or CUDA)
C:\Users\bruce\FAHBench_0_4>FAHBench.exe -platformId 0 -deviceId 0 -platform OpenCL -precision single --disable-splash
Explicit:
Checking for accuracy...done
5.84779 ns/day
Implicit:
Checking for accuracy...done
38.4752 ns/day
C:\Users\bruce\FAHBench_0_4>FAHBench.exe -platformId 0 -deviceId 0 -platform OpenCL -precision double --disable-splash
Explicit:
Checking for accuracy...done
1.80511 ns/day
Implicit:
Checking for accuracy...done
2.57122 ns/dayPosting FAH's log:
How to provide enough info to get helpful support.
How to provide enough info to get helpful support.
Re: Folding@Home Benchmark Beta (0.4 Latest)
Do you plan to port FAHBench to Linux or OSX any time soon?
Posting FAH's log:
How to provide enough info to get helpful support.
How to provide enough info to get helpful support.